DL字符定位
本节内容包含:
模块原理
DL字符定位是基于深度学习的方法实现的,其主要原理是对标注好的字符区域进行学习,提取其形态、轮廓等低层级信息以及高层级语义信息。相对于人为选择的特征,深度学习方法学习到的特征信息具有更好的表征性,因此可以获得更高的字符定位精度。
基于深度学习的字符定位算法,会给每个定位框输出一个得分,也称为置信度,用于表示该定位框是字符框的可能性大小。该定位框是字符框的可能性越大,则置信度越大;反之,置信度越小。
使用方法
DL字符定位模块主要用于将图像中感兴趣的字符区域检测出来,通过匹配大致的字符库信息来确定字符的位置。当文本背景复杂或者位置不固定时,通过DL字符定位能够实现精准的字符位置输出。
传统定位算法与深度学习定位算法的适用场景对比如下:
-
传统字符定位:传统定位算法主要有快速(高精度)特征匹配、Blob分析等。主要用于有固定特征且特征一致性较好,特征与背景对比度高且背景简单的场景。
-
深度学习字符定位:无固定定位特征,字符形态不止一种,对比度低,背景略带干扰,支持多行、任意角度(0~180°)字符定位。
DL字符定位模块一般搭配DL字符识别模块使用,将字符定位出来后,字符识别模块检测区域继承定位的ROI完成字符的识别。
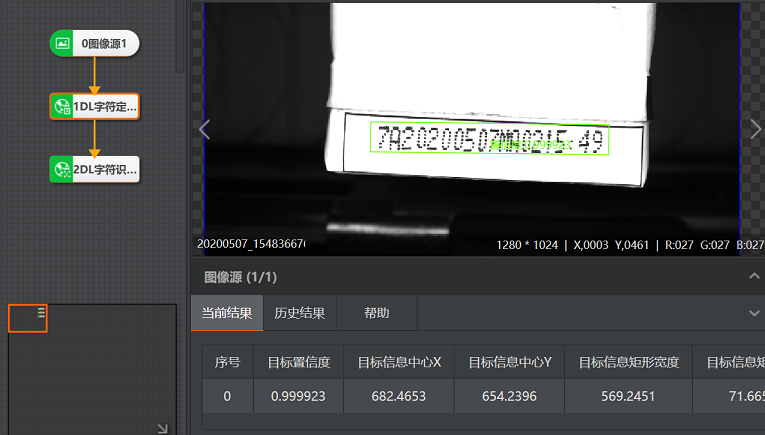 图 1 DL字符定位使用示例
图 1 DL字符定位使用示例DL字符定位模块对字符在图像的占比有要求,建议字符高度不小于图像长边的2%。若不满足要求,建议先初定位对图像进行裁剪。裁剪需要用到匹配(模版匹配、Blob分析)、定位修正、仿射变换等模块。
参数配置
- 模型文件路径
-
此处会提供默认模型,也可以自行加载训练好的模型文件。
- 方案存模型
-
使能后,将模型数据保存到方案文件或流程文件中,跨机加载方案时无需再次输入模型文件路径。
- 最大查找个数
-
即最大查找的字符框个数。若实际检测出的字符框数量M小于最大查找个数N,则实际显示M个字符框;若实际检测出的字符框数量大于N,则实际只能显示N个字符框。
- 最小置信度
-
图像内所有像素的最小置信度,低于该参数值的像素会被过滤,高于该参数值的像素区域会被计算成包围字符框。
- 最小平均分数
-
若包围字符框内所有像素的平均置信度小于该参数值,则不返回该字符定位结果;可根据实际需求进行设置,默认值为0.3。
- 最大重叠率
-
字符框允许被遮挡的最大比例。当实际重叠率超过该参数值时,则不定位该字符。一般来说,该参数无需调整。
- 目标排序
-
可选按中心点X坐标排序、按中心点Y坐标排序、按置信度排序。
-
按中心点X/Y坐标排序:按照目标中心X/Y坐标从小到大对结果信息进行排序。
-
按置信度排序:按照目标置信度从大到小对结果信息进行排序。
-
- 边缘筛选使能
-
使能后,需设置最小边缘分数。若查找目标在边缘内的部分占整体的比例小于最小边缘分数,则舍去该查找目标。
- 字符角度使能
-
默认关闭状态,使能后需配置字符角度范围,只会保留角度符合设置范围的字符框。
- 字符宽度使能
-
默认关闭状态,使能后需配置字符宽度范围,只会保留宽度符合设置范围的字符框。
- 字符高度使能
-
默认关闭状态,使能后需配置字符高度范围,只会保留高度符合设置范围的字符框。
模块结果
该模块的模块结果介绍请见DL字符定位。