DL字符识别
本节内容包含:
模块原理
字符识别是指利用神经网络来识别图像中的文本信息。一般来说,文本识别的输入图像应是文字图片,即定位好的文本行,所以文本识别一般与文本定位或者其他预处理配合使用。针对图像中的文字序列,通过自动学习得到的模型,转化为一组给定标签的输出序列。
根据识别对象的不同,字符识别可以划分为三种类型:单字识别、整词分类和整行识别(基于文本行序列的识别)。当能够定位出单字时,可以用图像分类的方法直接对单字进行分类;当需要预测的整词数量较少时,可以对整词进行分类;当有大量整词需要预测且没有单字定位时,就需要采用整行识别的算法。相较于前两种方法而言,整行识别无需考虑字符、单词个数,仅需识别一次,效率更高;同时还可以利用文本的上下文信息,识别准确率更高。DL字符识别模块使用的是整行识别方案,其工作流程大致如下。
-
Step1:特征提取。通过卷积操作提取图像不同层级的语义信息。
-
Step2:提取文字序列特征。借助循环神经网络中的LSTM层,将Step1中提取到的卷积神经特征转化为文字序列特征。
-
Step3:结果输出。将Step2输出的文字序列转化为字符信息。
模型性能调优
此处提供几种模型性能不佳的情况以及对应的模型性能调优方法。
|
类型 |
调优方法 |
|---|---|
|
通用模型识别结果不佳 |
|
|
自行训练的模型识别结果不佳 |
|
由于字体的影响,数字0和字母O、数字1和大写字母I、大写字母V和小写字母v等字体非常接近的情况,比较容易出现误识别,往往需要结合字符串的规则进行优化。
使用方法
深度学习字符识别是指通过AI技术将印在物体表面的字符转换成计算机可以识别的信息,简单来讲就是识别物体表面的字符信息。在工业领域,其被普遍应用在食药品包装、3C电子、汽车零配件生产、半导体、物流等行业,实现生产日期、批号、产品编号等信息的自动识别。
DL字符识别模块的适用场景兼容传统字符识别模块适用的所有场景。对于字符形态不止一种、对比度低、背景略带干扰、稍微黏连和畸变但是肉眼可辨的字符,该模块也适用,如下图所示。
 图 1 DL字符识别应用场景示例
图 1 DL字符识别应用场景示例对于DL字符识别模块,前序模块可搭配用于字符定位的模块,如DL字符定位、模板匹配、Blob分析等模块。若要判断字符打印是否正确,需要与标准字符信息做对比,后续模块可能需要用到字符比较模块,流程如下图所示。
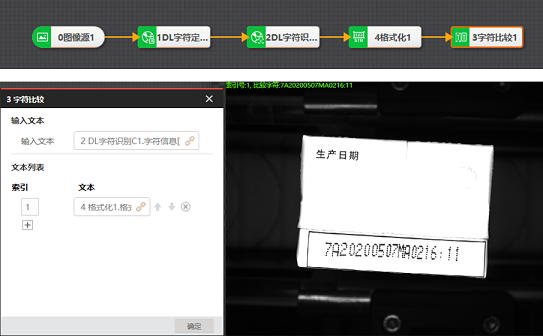 图 2 DL字符识别示例
图 2 DL字符识别示例参数配置
- 模型文件路径
-
此处会提供默认模型,也可以自行加载字符训练生成的模型文件。
- 方案存模型
-
使能后,将模型数据保存到方案文件或流程文件中,跨机加载方案时无需再次输入模型文件路径。
- 字符校验
-
单击字符校验会弹出字符校验窗口,启用字符校验后可设置自定义字符校验信息。
-
识别字符个数:表示每个文本行最多可输出的字符个数N,若实际识别出的字符数量M大于N,则只输出N个字符;若实际识别出的字符数量M小于等于N,则输出全部M个字符。
-
设置字符类型:通过设置每一个字符所属的字符类型,并按照这些字符类型对输出的结果进行过滤。字符类型包括全部、数字(0~9)、大写字母(A~Z)、小写字母(a~z)、特殊字符、空格和自定义。
说明:-
特殊字符:其覆盖范围为自定义字符类型中的特殊字符。
-
自定义:可根据需求对已有字符库中的字符选择组合形式,完成设置后将鼠标放置在自定义设置框上可以显示已设定的组合形式。
-
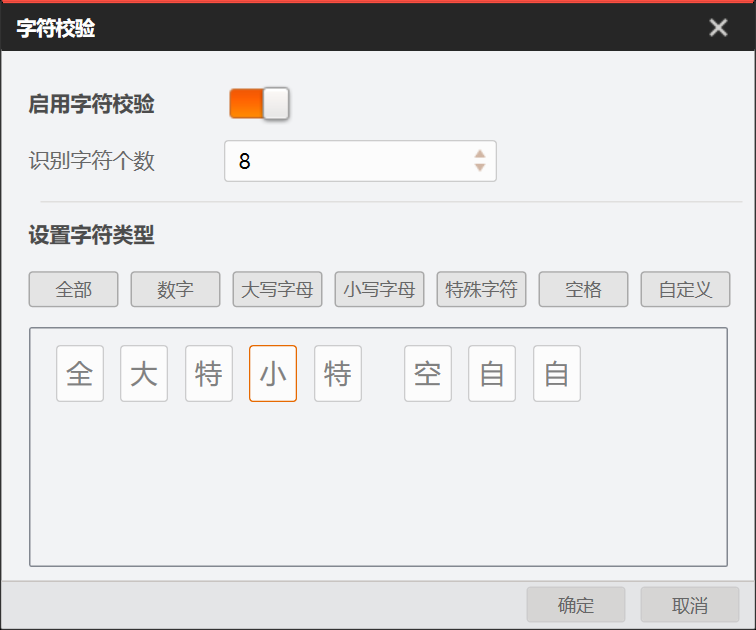 图 3 字符校验界面
图 3 字符校验界面 -
- 最小置信度
-
若检测结果的置信度(即识别内容为文本行的概率)小于所设置的最小置信度,则不返回该字符识别结果;用户可根据实际需求进行设置,默认值为0.5。
模块结果
该模块的模块结果介绍请见DL字符识别。