深度学习
深度学习是指通过类似脑神经网络的深度学习模型,让计算机像人一样在真实世界中吸收、学习和理解复杂的信息,完成高难度的识别任务,可用于图像分割、图像分类、目标检测、图像检索、异常检测和实例分割等。
深度学习需要基于一定的数据基础,所以在深度学习前需要对大量的数据集进行训练,参与训练的数据集要完成标签的标注,且应尽可能保证数据的多样性。 深度学习模型文件训练可使用深度学习训练工具(VisionTrain)。
深度学习相关模块均分为C和G两种类型,这两种模块的原理与参数基本一致,仅在于运行环境不同。后缀为“C”的模块是基于CPU运行的,后缀为“G”的模块是基于显卡GPU运行的。若使用CPU模块,则推荐使用i5及以上的CPU;若使用GPU模块,则推荐使用RTX系列或GTX16系列,需确保显存2GB及以上。
接下来,将从神经网络构成、训练、性能评估指标等方面进行基础介绍,以便更好地理解深度学习相关模块的使用原理。
神经网络构成
在机器视觉领域,深度学习算法一般是使用卷积神经网络(Convolutional Neural Network,CNN)。一般情况下,一个完整的卷积神经网络是由卷积层、归一化层、池化层、激活层、全连接层和输出层组成。
-
卷积层:卷积操作主要用于获取更加深层次的特征信息。如下图所示,输入图像是32*32*3,3是图像深度(即R、G、B三色通道),卷积层是一个5*5*3的卷积核,卷积核的深度必须和输入图像的深度相同,比如均为3。通过一个卷积核与输入图像的卷积可以得到一个28*28*1的特征图,下图是用两个卷积核得到了两个特征图。
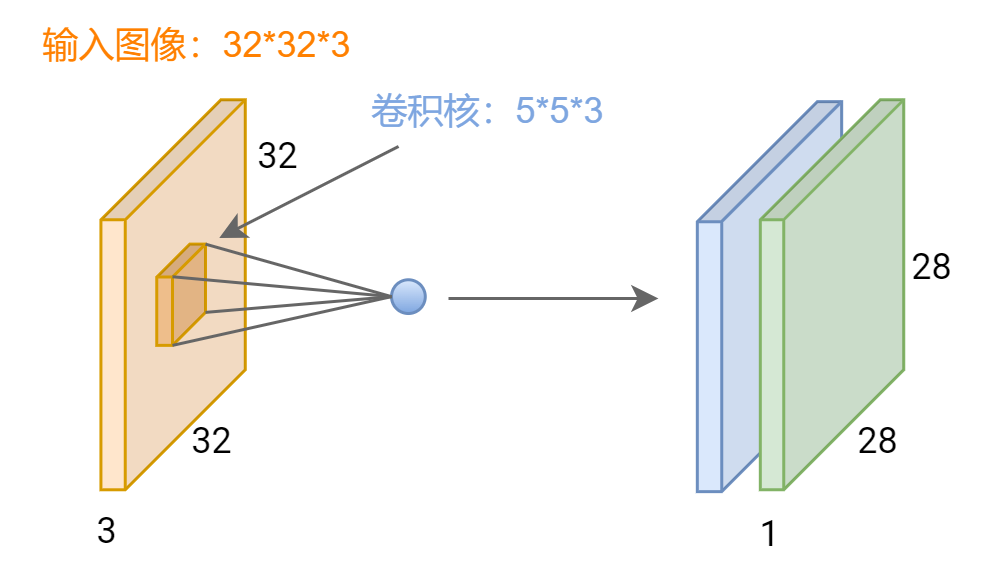 图 1 卷积示意图
图 1 卷积示意图而深度学习网络是通过多个卷积层串联起来形成的一个网络结构,使用更多的卷积操作可获得更加深层次的特征信息。
-
池化层:本质上是一种降采样的方式,一般出现在卷积层之后,用于降低因图像尺寸过大而带来的巨大计算量。此外,池化还能够提供平移和旋转不变性,以提升神经网络的鲁棒性。
目前主要有两种池化方式:均值池化和最大值池化。均值池化时对池化区域内的图像取平均值, 而最大值池化则是将池化区域的像素点取最大值。
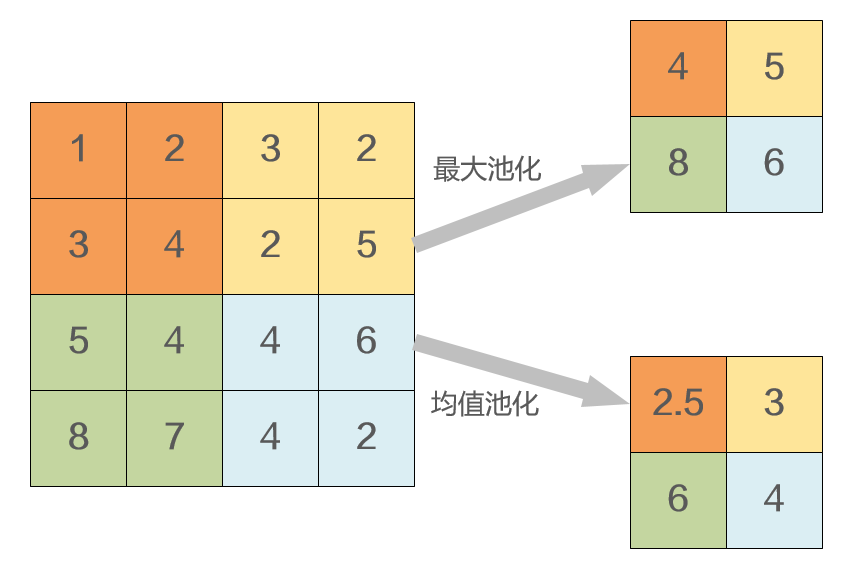 图 2 均值池化和最大池化
图 2 均值池化和最大池化 -
激活层:激活函数决定了某个神经元是否被激活,以及这个神经元接受到的信息是否有用。激活函数的形式如下:
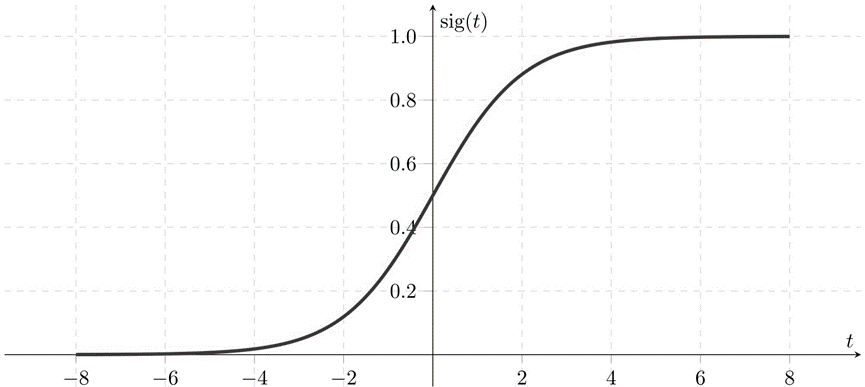 图 3 激活函数示意图
图 3 激活函数示意图对于y=ax+b 这样的线性函数,当x的输入很大时,y的输出也是无限大或无限小的。如果没有激活层的话,经过多层网络叠加后,值无任何收敛趋势,这显然不符合预期。激活函数的非线性变换则可以使得神经网络能够处理更加复杂的任务。
-
输出层: 用于将神经网络提取的特征转化为所需结果。比如,对于分类任务,输出层是将特征图或特征向量转化为置信度和类别信息;对于目标检测任务而言,则需将特征图转化为目标的定位框、类别及置信度;对于字符识别任务而言,则是将结果转化为对应的字符串信息。
神经网络模型训练
训练是指按照特定的学习算法将卷积神经网络中的权重参数不断进行调整,以达到局部最优的状态。如下图所示,神经网络的起始点在误差较大的红色区域,随着学习的过程,误差会沿着黑色线条逐步下降到误差较低的蓝色区域,需要注意的是,一般来说,这仅仅是一个局部最优解。在这一过程中,会涉及到几个重要的概念:迭代次数、学习率、预训练模型。
-
迭代次数:表示模型进行训练的次数,即权重更新的次数,对应图中黑色的节点。迭代次数越大,模型权重越接近于局部最优解。
-
学习率:表示每一次权重参数调整的幅度,对应图中黑色节点的距离,学习率越大,权重变化幅度越大,但有一定几率导致模型无法准确收敛;学习率越小,权重变化幅度越小,但可能导致模型学习不够充分,无法达到局部最优解。
-
预训练模型:为了神经网络能够更快进行收敛,提前在大规模数据集上训练好的一组权重参数,相对于权重参数随机初始化,这组权重参数会更加合理,也会使得模型起始点就更接近于局部最优解。
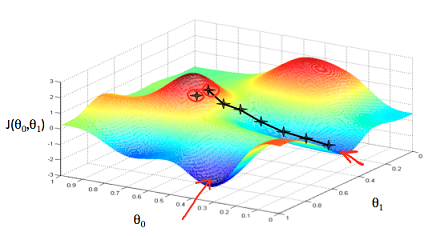 图 4 随机梯度下降示意图
图 4 随机梯度下降示意图性能评估指标
-
混淆矩阵:即统计分类模型的预测结果,并以矩阵的形式将其展示出来。
-
TP:真实类别为正类,被预测为正类。
-
FP:真实类别为负类,被预测为正类。
-
FN:真实类别是正类,被预测为负类。
-
TN:真实类别是负类,被预测为负类。
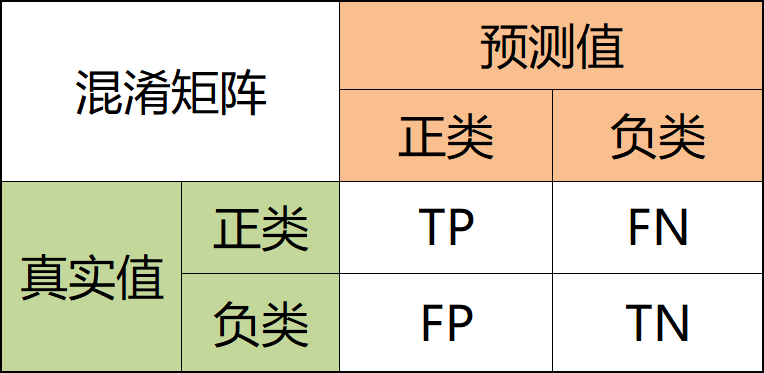 图 5 混淆矩阵
图 5 混淆矩阵 -
IoU(交并比):指预测框与原标记框的交叠率,即它们的交集与并集的比值。若二者完全重叠,则比值为1。计算公式如下:

其中,CIoU是指每个类别的平均IoU,IoUc表示c类别中的框的IoU,numc表示类别c的目标个数;MIoU表示所有类别的平均IoU,class_num表示类别数。
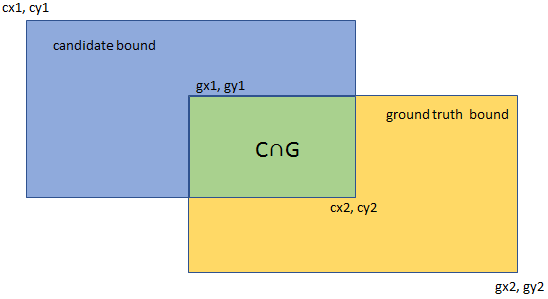 图 6 IoU示意图说明:
图 6 IoU示意图说明:这里的预测框和标记框是指多点模式标注的多边形,而不仅仅是矩形框。
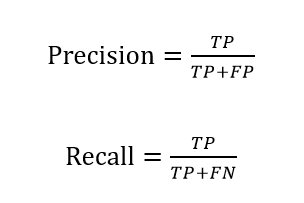
Precision(精确率)与Recall(召回率):Precision是指预测为正确的数据中真实值为正确的比例,Recall是指在所有真实值为正确的数据中有多少被预测正确。
F1_Score:又称平衡F分数,同时兼顾了分类模型的精确率和召回率,其最大值是1,最小值是0。计算公式如下:
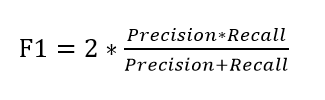
各算法模块与对应指标
|
算法模块 |
推荐评价指标 |
|---|---|
|
分类 |
混淆矩阵、Precision、Recall、PR曲线、F1_Score |
|
图像分割 |
Recall、Precision、M_IoU |
|
实例分割 |
Recall、Precision、PR曲线 |
|
目标检测 |
Recall、Precision、M_IoU、PR曲线、F1_Score、mAP、AP@0.5:0.95 |
|
文本定位 |
Recall、Precision、PR曲线、F1_Score |
|
字符识别 |
行准确率 |