DL分类
本节内容包含:
模块原理
基于深度学习的图像分类技术,本质上是利用神经网络提取图像特征,并根据其特征分布情况给出类别信息。一般来说,对于一张图像,分类网络只会给出预测的类别信息以及该图片属于该类别的可能性,即得分或置信度。
一个典型的分类神经网络,其工作流程大致如下:
-
Step1:特征提取。通过卷积操作可以提取图像不同层级的特征,随着卷积层数的增加,所提取的特征从最开始的轮廓、灰度、角点等表层特征,逐步转化为结构、关系等高层级的语义特征。。
-
Step2:特征降采样。通过池化层可以实现图像的降采样,一方面可以降低网络的计算量,另一方面可以增加卷积的感受野(卷积神经网络每一层输出的特征图上的像素点在输入图片上映射的区域大小),使得卷积可以感知到更大区域的特征分布。。
-
Step3:特征激活。基于Relu等激活层进行特征激活,可以增加网络的非线性,使得网络能够更好地拟合不同的图像特征。。
-
Step4:分类。通过全连接层和分类器将提取到的一组特征进行分类,得到当前图像属于不同类别的可能性。。
模型性能调优
此处提供几种模型性能不佳的情况以及对应的模型性能调优方法。
|
问题类型 |
可能原因 |
调优思路 |
|---|---|---|
|
模型仅输出一个类别 |
数据集中类别分布不均,某一类别数据占据绝大部分,导致模型过拟合 |
可考虑增加训练数据集的样本数量以缓解过拟合问题。 |
|
模型准确率整体较低 |
数据量较少 |
需增加数据量,一般建议单类别20张以上,同时考虑适当增加数据增强。 |
|
训练效果不佳 |
可对训练集进行测试,分为以下两种情况:
|
|
|
模型部分类别准确率低 |
数据量少或数据标注错误 |
可考虑增加数据量或完善数据标注操作。 |
|
模型整体性能较高,仍存在少量样本误分 |
一般是模型泛化能力不够或者该类样本属于困难样本 |
需对误分样本进行分析,分为以下两种情况:
|
使用方法
深度学习分类通过学习每个目标类别的图像特征,以准确区分各个目标的种类。它利用计算机对图像进行定量分析,把图像或图像中的每个像元或区域归为若干个类别中的其中一类,以代替人的视觉判读,在物体识别、分拣方面有广泛应用。该模块适用于简单的缺陷检测、产品分类场景。使用DL分类模块时,建议图像中目标物体在全局视野中的占比较大。
当类内差异较小、类间差异较大时,且类别会不断增加可以推荐使用DL图像检索。
该模块一般与图像源模块直接配合使用,然后在DL分类模块中加载训练好的模型文件即可。
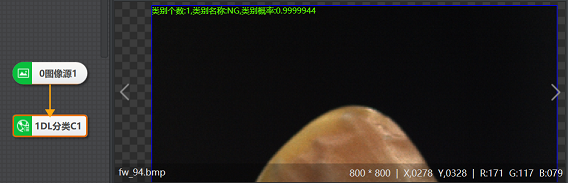 图 1 DL分类示例
图 1 DL分类示例参数配置
以下仅介绍该模块的运行参数详情。通过配置运行参数,可定义当前模块如何处理输入的数据。
模块结果
该模块的模块结果介绍请见DL分类。