DL实例分割
本节内容包含:
模块原理
实例分割是指利用神经网络提取图像中待测目标掩膜的方法,可以精确输出每一个目标实例的掩膜信息。
图像分割和实例分割的主要区别在于,图像分割会赋予同一类别的物体相同的像素值,实例分割会为每一个物体分别赋予一个像素值,即使是同类的目标,也会给予不同像素值,使得用户可以获取到每一个目标独立的掩膜信息。基于这一特性,实例分割适用于对检测精度要求较高的定位、计数场景。
从算法实现来看,实例分割方法大多是基于目标检测结果展开的,将检测到的ROI区域用作前背景进行二类分割。
模型性能调优
此处提供几种模型性能不佳的情况以及对应的模型性能调优方法。
|
问题类型 |
调优思路 |
|---|---|
|
输出结果较差 |
|
|
误检数据较多 |
可考虑采用背景图模式,将一些易被误检的正常样本设置为参考图像进行学习 |
|
漏检数据较多 |
|
|
掩膜质量较差 |
|
使用方法
DL实例分割模块主要用于将输入图像中的目标检测出来,并对目标的每个像素分配类别标签,以区分不同实例。DL实例分割模块可用于检测产品中的缺陷,也可用于识别图像中的特定物体,如下图所示。
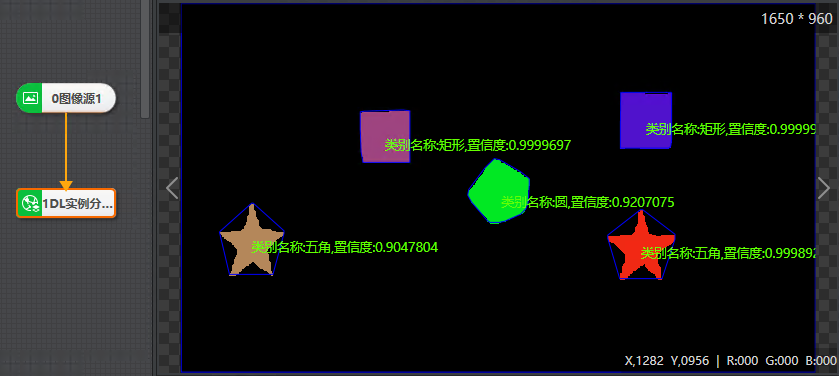 图 1 DL实例分割示例效果图
图 1 DL实例分割示例效果图参数配置
以下仅介绍该模块的运行参数详情。通过配置运行参数,可定义当前模块如何处理输入的数据。
- 模型文件路径
-
加载已训练好的模型文件。
- 方案存模型
-
使能后,将模型数据保存到方案文件或流程文件中,跨机加载方案时无需再次输入模型文件路径。
- 最大查找个数
-
即最大查找的目标个数。若实际检测出的目标数量M小于最大查找个数N,则实际显示M个目标;若实际检测出的目标数量大于N,则实际只能显示N个目标。
- 目标框置信度
-
若检测结果的置信度(即识别内容为字符框的概率)小于所设置的最小置信度,则不返回该字符定位结果;用户可根据实际需求进行设置,默认值为0.5。
- 目标框重叠率
-
目标允许被遮挡的最大比例。当实际重叠率超过该参数值时,则不识别该目标框。
- 掩膜置信度
-
掩膜得分的最小值。当掩膜实际得分低于该参数值时,则不输出该掩膜区域。
- 掩膜重叠率
-
两个掩膜区域重叠程度的最大值。当实际重叠率超过该参数值时,则过滤掉置信度较低的掩膜区域。
模块结果
该模块的模块结果介绍请见DL实例分割。