DL目标检测
本节内容包含:
模块原理
DL目标检测是指利用神经网络提取图像中待测目标位置信息的方法。从目标检测算法的实现角度来看,可以分为二阶段和一阶段两种模式。
-
二阶段目标检测:第一阶段先进行前背景检测生成候选框,第二阶段对候选框进行精定位并给出其类别信息。
-
一阶段目标检测:直接输出待测目标的位置和类别信息。
相较于二阶段目标检测而言,一阶段目标检测在性能相当的基础上,推理效率更高,且更容易训练。因此,在实际场景下大多都是使用一阶段的目标检测算法。这里将结合一阶段目标检测算法进行详细介绍。
一阶段的目标检测网络结构,可以大致分为特征提取、多尺度特征融合、特征检测与结果输出几部分。其工作流程大致如下:
-
Step1:特征提取。该部分属于目标检测的主干部分backbone,由多个前后堆叠的、由卷积、池化、激活层构成的特征提取单元,用于提取图片中的不同层级的语义信息。
-
Step2:多尺度特征融合。该部分为目标检测的Neck,基本均是采用特征金字塔结构(FPN)进行上采样操作,并与backbone提取的不同层级的特征进行融合,从而获取待测目标不同层级的特征信息,以增强目标检测网络对于不同大小目标的检测能力。
-
Step3:特征检测。该部分为目标检测的Head,基于多尺度特征融合的结果学习定位框信息和类别信息,并将不同层级的框与类别信息进行融合。
-
Step4:结果输出。将预测结果按照所需的格式进行解析并输出。
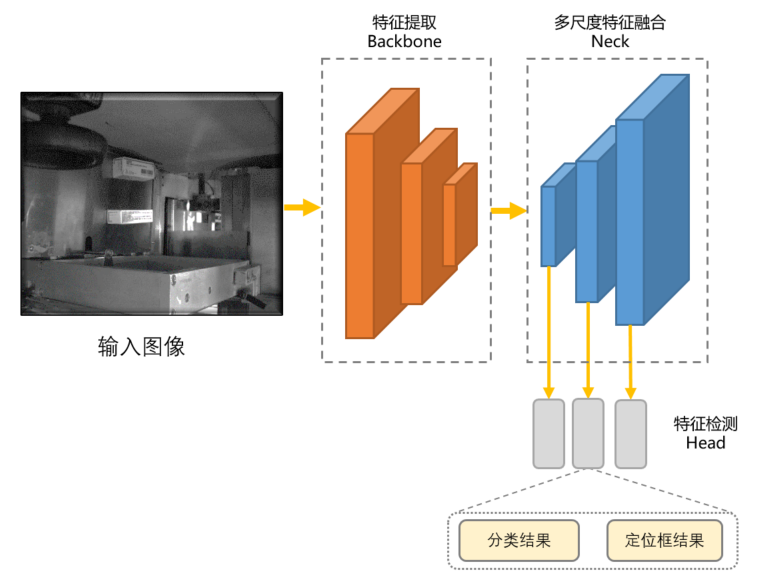 图 1 目标检测网络结构示意图
图 1 目标检测网络结构示意图使用方法
DL目标检测是指利用神经网络提取图像中待测目标位置信息的方法,它将目标的定位和分类合二为一,具备准确性和实时性。尤其是在复杂场景中,可对多个目标进行实时处理,自动提取和识别目标。该模块适用于定位、计数、缺陷检测等场景。
 图 2 DL目标检测示例
图 2 DL目标检测示例参数配置
以下仅介绍该模块的运行参数详情。通过配置运行参数,可定义当前模块如何处理输入的数据。
- 模型文件路径
-
加载已经训练好的模型文件。
- 方案存模型
-
使能后,将模型数据保存到方案文件或流程文件中,跨机加载方案时无需再次输入模型文件路径。
- 获取模型ROI
-
启用后,可直接获取模型文件中图片的ROI区域。此时基本参数中的ROI区域无法设置。
- 按ROI裁图
-
启用该功能后,模块运行时会将ROI内区域提取出来,仅对区域内图像进行预测;不启用时,则对整张图片进行识别,但会按照ROI范围以及边缘筛选使能、最小边缘分数对检测结果进行筛选过滤。
- 最大查找个数
-
即最大查找的目标个数。若实际检测出的目标数量M小于最大查找个数N,则实际显示M个目标;若实际检测出的目标数量大于N,则实际只能显示N个目标。
- 最小置信度
-
即定位框的最小得分。若实际得分小于该参数值,则不返回该目标检测结果。
- 最大重叠率
-
目标图像允许被遮挡的最大比例。
- 目标排序
-
可选按中心点X坐标排序、按中心点Y坐标排序、按置信度排序。
-
按中心点X/Y坐标排序:按照目标中心X/Y坐标从小到大对结果信息进行排序。
-
按置信度排序:按照目标置信度从大到小对结果信息进行排序。
-
模块结果
该模块的模块结果介绍请见DL目标检测。